A new study just relased provides a detailed and technical overview of some key methods for reducing the risk of hallucinations in Large Language Models (LLMs).
As large language models (LLMs) like ChatGPT captivate the public imagination with their eloquence, researchers grapple with these systems’ tendency to conjure up convincing but false information – a phenomenon dubbed “hallucination”. Mitigating such imagination run amok represents AI’s next frontier if these powerful models are ever to be safely deployed for real-world usage.
The risks are evident across potential LLM applications, whether answering medical or legal queries, analyzing financial reports, or summarizing customer conversations. The sheer breadth of training on vast swathes of internet text equips LLMs with exceptional linguistic fluency but also the capacity to subtly distort information based on underlying biases. Researchers have identified the snowballing effect where initial erroneous text triggers further hallucinations down the line.
Dozens of techniques have emerged to detect and diminish these products of AI imagination. As highlighted in an extensive academic literature review, approaches range from simple tweaks to how humans provide queries to LLMs all the way to fundamentally altering model architectures.
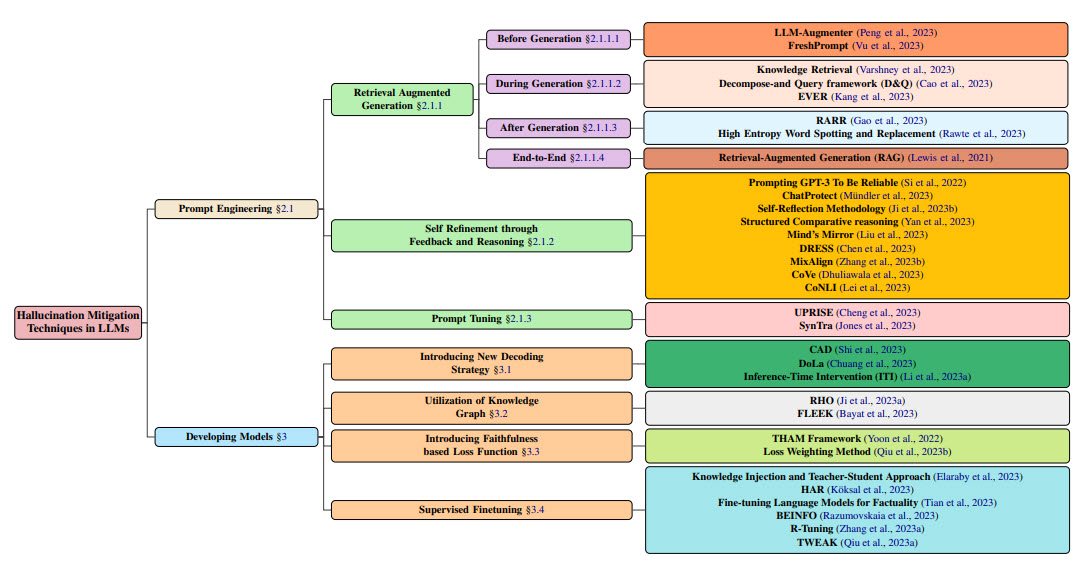
On the query side, techniques include asking an LLM to verify its own responses by generating additional self-checking questions. Other strategies dynamically refine prompts by extracting relevant evidence from search engines to ground the model’s responses in factual reality.
Several methods tackle detecting hallucinations post generation, for instance by algorithmically replacing high-entropy dubious words with safer alternatives. Such system-agnostic techniques hold promise for cross-compatibility.
More complex approaches require re-engineering model innards, for example by introducing separate decoding steps that emphasize factual knowledge within a model while generating text. Researchers also enrich models with external information sources such as knowledge graphs to reduce unmoored imagining.
Exploring open-ended human feedback also shows promise, with one method called DRESS that uses a vision-language model to align responses with preferences indicated through natural critique and refinement suggestions. So far experiments rely on synthetic data, avoiding the need to scale costly human involvement.
As models grow ever larger, one line of inquiry distills self-evaluation skills from massive teachers into more easily deployed student models, echoing how humans might impart common sense. The concept of refusal also arises, with models taught to recognize the limits of their knowledge and decline inappropriate queries.
“We have to curb the undesirable urge towards imaginative speculation in AI systems intended to inform human activities and decisions,” urged Dr. Henry Wu, an LLM safety researcher at Oxford, in an interview. “That is the only way societal acceptance and adoption will grow.”
The breadth of approaches underscored in the literature analysis highlights how seriously scientists contend with the threats of unconstrained LLM hallucinations. Constructing holistic defenses spanning data inputs, model architectures and human collaboration appears essential given AI’s central role in everyday information ecosystems.
“Getting AI right could mean the difference between empowerment and harm at a societal level,” said Dr. Wu. “As emerging models display more human-like discourse capacities, we must instill machines with the same doubt, curiosity and scientific integrity that characterizes human wisdom.”
The path ahead remains unclear, but understanding hallucination’s risks crystallizes the challenge of developing AI that not only dazzles but enlightens. As researchers persist in tweaking prompts and neural connections to keep imagining in check, the collective dream of imbuing machines with grounded understanding edges closer. The stakes could not be higher.
The original paper on which this article is based can be found at:
Tonmoy, S.M., Zaman, S.M., Jain, V., Rani, A., Rawte, V., Chadha, A. and Das, A., 2024. A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models. arXiv preprint arXiv:2401.01313.