Whose model is reading your data?
Almost every AI feature a UK business now uses — the assistant in the inbox, the summary in the meeting, the chatbot on the website — is powered by a large language model (a system trained to predict and generate text) controlled from the United States. We read the providers’ own privacy, licensing and data-boundary pages to ask where your data actually goes when you press send, and whether there is a real way out.
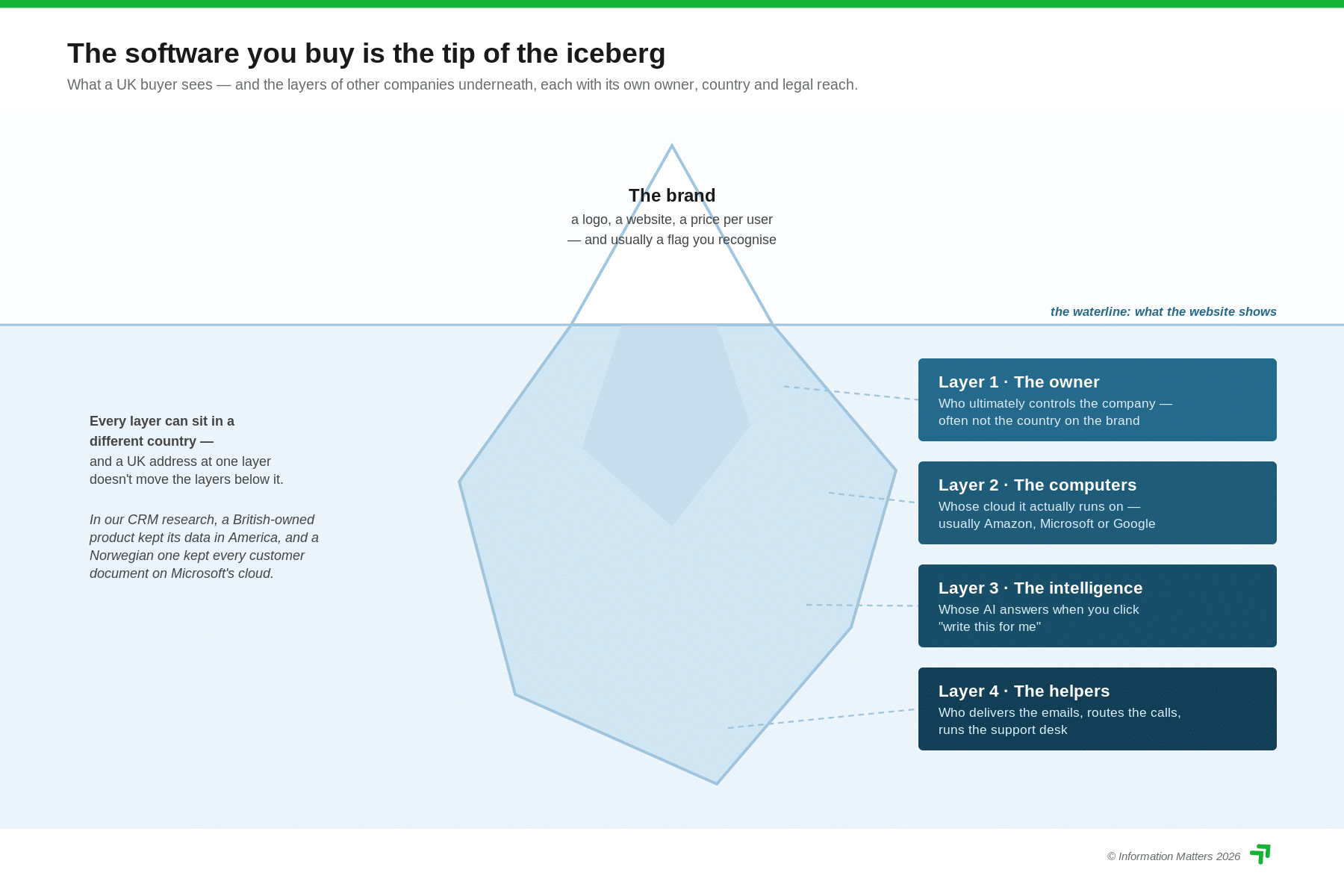
A large language model is the engine; everything else in the modern software stack is increasingly just a steering wheel bolted on top. So the sovereignty question for artificial intelligence is not really about the chat window your staff see. It is about the handful of companies that own the engines, the legal systems those companies answer to, and whether the data boundary you carefully paid for actually holds once an AI feature is switched on.
The honest summary up front: the frontier is American. Of the eight providers UK businesses realistically call, six are controlled from the United States, one from France and one from Canada. That matters because of two US statutes — the CLOUD Act (the Clarifying Lawful Overseas Use of Data Act, which can compel a US company to hand over data it controls, wherever in the world that data is stored) and FISA Section 702 (Foreign Intelligence Surveillance Act surveillance powers that reach foreign users of US communications providers). Where a company is controlled, not where a server sits, is what decides whose laws can reach the data.

The gate inside the fence
Start with the finding that should change how UK buyers read their own contracts. Microsoft 365 Copilot is, by Microsoft’s own documentation, an EU Data Boundary service for European customers, running on Azure OpenAI rather than the public OpenAI service [1]. That is the reassurance most enterprise buyers bought.
But the same Microsoft page now states, in plain words, that “Anthropic models are out of scope for the EU Data Boundary” (the full sentence adds “and when available, in-country LLM processing commitments”), and that starting 7 January 2026 Anthropic is a subprocessor for Microsoft 365 Copilot [1]. Anthropic, the maker of the Claude models, is US-controlled; under its own commercial terms the contracting entity for UK, EEA and Swiss customers is Anthropic Ireland, Limited (with Irish governing law), while the ultimate parent is Anthropic, PBC in the US [2]. So a UK organisation that pinned its tenant to a UK or EU region, and reasonably assumed the boundary held, may find a class of AI requests handled by a supplier Microsoft itself places outside that boundary. The fence is real. The newest gate in it is documented in the subprocessor notes, not the sales deck — and it is the single most important thing to check before turning Copilot features on.

What the providers actually promise
The good news, read directly from the providers’ own pages, is that the major model makers have converged on a similar set of enterprise commitments — and they are stronger than many buyers assume.
OpenAI (US, controlled by the OpenAI Foundation) states it does not train its models on business data by default, that the customer owns inputs and outputs, and that interface (API) data is retained for at most 30 days unless legally required — with a zero-data-retention option for qualifying use cases [3]. Anthropic’s commercial terms say plainly that it “may not train models on Customer Content” [2]. Google, for its Gemini models on the Vertex AI platform, points to a contractual restriction on training on customer data and documents a zero-data-retention path for qualifying workflows; default short-term retention for abuse-monitoring applies unless ZDR is configured [4]. Amazon’s Bedrock — the route by which UK businesses reach many models, including Anthropic’s, through Amazon Web Services — is built so that the model providers themselves get no access to customer prompts or outputs [5].
Two patterns are worth holding onto. First, “we don’t train on your data” is now table stakes, but it is a default that can be switched, and several providers retain data briefly for abuse monitoring unless you opt out. Second, none of these commitments changes the controller’s nationality, and therefore none of them removes US legal reach. A no-training promise is a privacy commitment, not a sovereignty one.
The open-weight escape route — real, and narrower than it looks
The genuine alternative to renting an American engine is to run an open-weight model — one whose trained parameters you can download and run on infrastructure you choose, including UK or EU data centres — yourself. Two names dominate, and both come with fine print.
Meta’s Llama models (Meta is US-controlled; under the Llama 4 licence, users in the EEA or Switzerland contract with Meta Platforms Ireland Limited, while UK and all other users contract with Meta Platforms, Inc.) are distributed under the Llama 4 Community License, not a standard open-source licence. You may use, modify and redistribute the weights royalty-free, but you must display “Built with Llama”, prefix any derivative model’s name with “Llama”, and — the real catch — if your product has more than 700 million monthly active users, you must request a separate licence from Meta, granted at Meta’s discretion [6]. For almost every UK business that ceiling is irrelevant; the point is that this is a controlled grant, governed by Californian law, not a no-strings release.
Mistral (France) is the European flagship, and the nuance matters. Its general-purpose smaller models — Mistral 7B, the Mixtral family, Mistral Small 3 — are released under the genuinely open Apache 2.0 licence: free to download, modify and use commercially, run anywhere [7]. But its larger flagship, Mistral Large 2, ships under the Mistral Research License, which permits research and non-commercial use only; commercial self-deployment requires a paid commercial licence [8]. So “use the European open model” is true for the small models and conditional for the big one.
Cohere (Canada) sits between the camps: a closed frontier provider, but one that offers private deployment inside your own virtual private cloud or on-premises, with an opt-out of model training and a stated commitment not to access your infrastructure or data [9]. For an organisation whose objection is “I don’t want my data leaving my walls” rather than “I don’t want a US engine”, that is a credible middle path.
The trade-off of going open-weight is honest work: you take on the hosting, the security patching, the evaluation and the bill for the graphics processing units (GPUs — the specialised chips that run these models). What you buy is control over where the model runs and whose law reaches it.

The compute floor: it’s American chips all the way down
Beneath every model — open or closed, sovereign-hosted or not — sits silicon. The frontier training and inference chips are overwhelmingly Nvidia GPUs, and Nvidia is a US company. This is where the UK’s own sovereign-compute effort meets its sharpest irony.
Britain’s flagship public AI machine, Isambard-AI, operated by the University of Bristol, is the centrepiece of the government’s AI Research Resource (AIRR). By the government’s own June 2026 guidance it is built from 5,448 Nvidia GH200 Grace-Hopper superchips, supplied by HPE — both American suppliers — with a sister machine, Dawn at Cambridge, running 1,024 Intel GPUs [10]. The government has committed over roughly £350 million to the two clusters by 2030, inside a £1 billion plan announced in January 2025 to scale national compute twentyfold [10]. It is a real and significant sovereign capability — the data and the operator are British, the access rules require UK-based projects — but the engines and the chips inside them are imported from the United States. Sovereign compute, on non-sovereign silicon.

The eight, at a glance
| Model / Provider | Controlled from | Open-weight? | Data boundary | Notes |
|---|---|---|---|---|
| OpenAI — ChatGPT / API [3] | USA (OpenAI Foundation) | No (closed) | No EU/UK boundary; ZDR option, ≤30-day API retention | No training on business data by default; customer owns inputs/outputs |
| Anthropic — Claude [2] | USA (ultimate parent Anthropic, PBC; UK/EEA/Swiss contracting entity Anthropic Ireland, Limited) | No (closed) | Out of scope for EU Data Boundary inside M365 Copilot [1] | “May not train models on Customer Content”; M365 subprocessor from 7 Jan 2026 |
| Google — Gemini (Vertex AI) [4] | USA (listed, Alphabet) | No (closed) | Contractual restriction on training on customer data; ZDR path for qualifying workflows | Reachable region-by-region on Google Cloud |
| Microsoft 365 Copilot [1] | USA (listed) | No | EU Data Boundary service — except Anthropic models, which sit outside it | Runs on Azure OpenAI; suppliers include OpenAI + Anthropic |
| AWS Bedrock [5] | USA (listed, Amazon) | Hosts both | Region-selectable; AWS shared-responsibility model | Model providers get no access to customer prompts/outputs |
| Meta — Llama [6] | USA (Meta; EEA/Swiss via Meta Platforms Ireland, UK via Meta Platforms, Inc.) | Yes — community licence | Yours — run on UK/EU infrastructure of your choice | 700M-monthly-user ceiling needs Meta’s separate licence; “Built with Llama”; California law |
| Mistral [7][8] | France | Mixed — small models Apache 2.0; flagship research-only | Yours — self-host anywhere | Mistral Large 2 needs a paid commercial licence for commercial self-deployment |
| Cohere [9] | Canada | No (closed, but private-deployable) | Your VPC / on-premises option | Opt-out of training; states no access to your infrastructure or data |
| Nvidia GPUs / Isambard-AI (AIRR) [10] | USA (chips) / UK (operator) | n/a | UK soil, UK operator; US silicon | 5,448 Nvidia GH200 via HPE; UK-only project access |
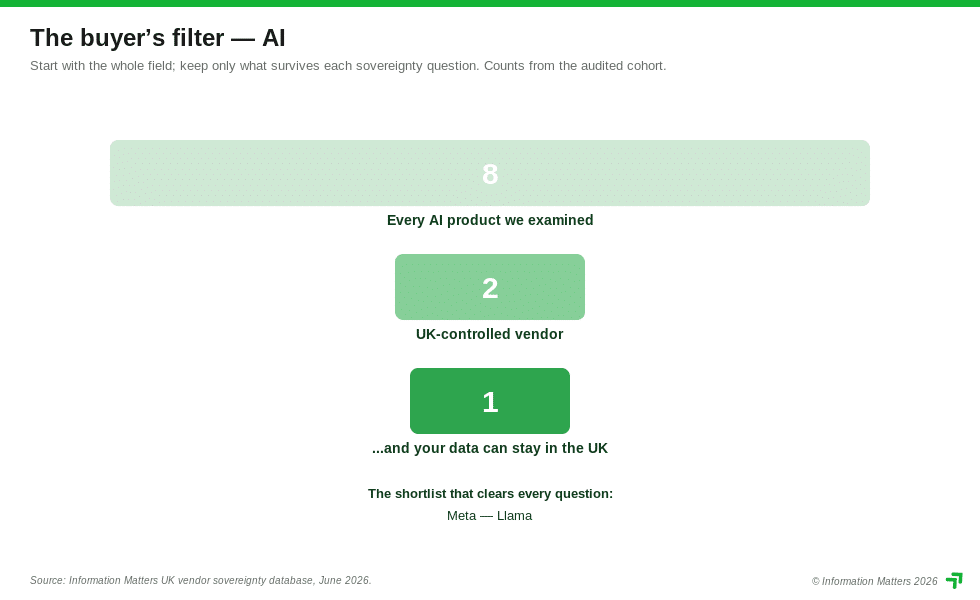
What buyers should take from this
The dial that runs through this whole series applies cleanly here. At one end, take the convenient default — a US frontier model inside a US productivity suite — and accept that no-training promises are privacy guarantees, not protection from US legal reach. The buyer’s job at this end is configuration: which AI features are on; which model suppliers power them; and crucially, do any of those suppliers sit outside the data boundary you paid for. Microsoft’s own Anthropic disclosure shows that last question is no longer hypothetical.
A step along, route your AI through a private deployment — Cohere in your own cloud, or any model on Bedrock with regions pinned and zero-retention set — so the data stays inside your walls even if the engine is foreign. At the far end, run open-weight models (Mistral’s Apache-licensed range, or Llama within its community-licence limits) on UK or EU infrastructure, and own the boundary outright — paying for it in hosting, security and GPU bills.
What this category adds to the series is the reminder that sovereignty has layers. You can hold the application, lose the model; hold the model, lose the chip. The UK’s own supercomputer makes the point: British data, British operator, American silicon. The practical move is not purity but knowing, at each layer, whose hand is on the switch — and the AI features now embedded across your stack are the layer where that hand changed most recently, and most quietly.

Sources
All facts are taken from each provider’s own published documentation — privacy, enterprise-data, licensing and trust pages — and from UK government guidance, read directly during June 2026. One primary reference per entity.
- Microsoft — Data, Privacy, and Security for Microsoft 365 Copilot (EU Data Boundary; “Anthropic models are out of scope for the EU Data Boundary”; Anthropic subprocessor from 7 January 2026), updated 9 March 2026: https://learn.microsoft.com/en-us/copilot/microsoft-365/microsoft-365-copilot-privacy
- Anthropic — Commercial Terms of Service (contracting entity Anthropic Ireland, Limited for UK/EEA/Switzerland under Irish governing law; ultimate parent Anthropic, PBC, USA; “Anthropic may not train models on Customer Content from Services”), effective 17 June 2025: https://www.anthropic.com/legal/commercial-terms
- OpenAI — Enterprise privacy (no training on business data by default; customer owns inputs/outputs; ≤30-day API retention; zero-data-retention option), updated 8 January 2026: https://openai.com/enterprise-privacy/
- Google Cloud — Vertex AI / Gemini data governance and zero data retention (contractual restriction on training on customer data; zero-data-retention path for qualifying workflows; default short-term retention for abuse monitoring unless ZDR configured): https://docs.cloud.google.com/gemini-enterprise-agent-platform/resources/zero-data-retention [Note: Google’s data-governance pages are JavaScript-rendered; specific retention-window figures were not confirmable from a clean primary fetch this session and over-specific claims have been softened accordingly.]
- Amazon Web Services — Amazon Bedrock data protection (model providers have no access to customer prompts and completions; shared-responsibility model): https://docs.aws.amazon.com/bedrock/latest/userguide/data-protection.html
- Meta — Llama 4 Community License Agreement (royalty-free limited licence; “Built with Llama”; 700 million monthly-active-user threshold requires a separate Meta licence; California governing law), effective 5 April 2025: https://www.llama.com/llama4/license/
- Mistral AI — Mistral Small 3 announcement (general-purpose models released under Apache 2.0; weights free to download, modify and use in any capacity), 30 January 2025: https://mistral.ai/news/mistral-small-3/
- Mistral AI — Mistral Large 2 (“Large Enough”) announcement (flagship released under the Mistral Research License, research/non-commercial only; commercial self-deployment requires a paid Mistral Commercial Licence), 24 July 2024: https://mistral.ai/news/mistral-large-2407/
- Cohere — AI Security and Data Protection (private deployment via VPC / on-premises / Model Vault; opt out of model training; “We won’t have access to your computing infrastructure or data”): https://cohere.com/security
- UK Government (DSIT / UKRI) — AIRR advanced supercomputers for the UK (Isambard-AI: 5,448 Nvidia GH200 Grace-Hopper superchips supplied by HPE, operated by the University of Bristol; Dawn: 1,024 Intel GPUs; c.£350m by 2030; £1bn twentyfold scale-up announced January 2025; UK-only project access), updated 4 June 2026: https://www.gov.uk/government/publications/ai-research-resource/airr-advanced-supercomputers-for-the-uk
Research notes: all facts from providers’ own published documentation — privacy, enterprise-data, licensing and trust pages — and from UK government guidance, read directly during June 2026. Supplier lists, data boundaries and model licences change; check the current documents before relying on them. This article reflects the opinions of the Information Matters team — human and AI — and should not be considered statements of fact.
If you have any questions or comments about this article please email info@informationmatters.net