Download AI Data Curation Market Forecast report
As the artificial intelligence landscape transitions from experimental “wow” moments to mission-critical “work” phases, a fundamental shift in strategy is occurring. The industry is moving past model-centric development, where the size of the neural network was the primary focus, into an era where the “curation” layer determines success. According to our latest research, the AI Data Curation market is projected to skyrocket from a $82.05 billion valuation in 2025 to $253.23 billion by 2030.
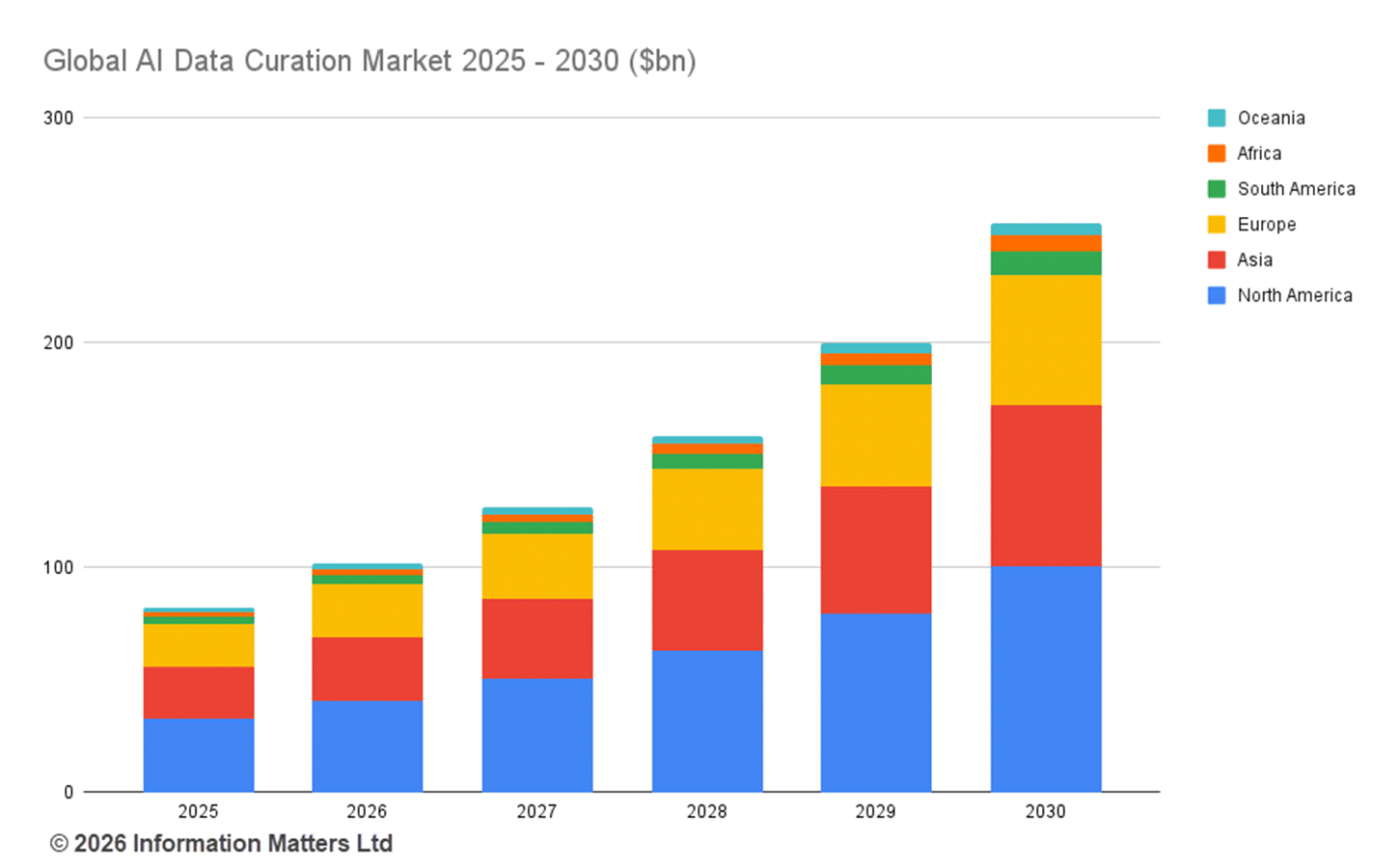
This growth is fueled by a simple business reality: the performance, safety, and ROI of AI are entirely dependent on the quality of the information fed into it.
The Architecture of Growth: Five Pillars of Curation
The curation market is no longer a monolithic block; it has matured into a sophisticated ecosystem. The report identifies five primary domains that manage the lifecycle of information from raw ingestion to the “last mile” of user delivery.
1. Ingestion & Transformation: The Gateway to Data Value
Enterprises are currently sitting on a “zettabyte era” deluge, with unstructured data projected to surpass 175 zettabytes in 2025. The challenge is that most business value is trapped in non-tabular formats like legal contracts, sensor logs, and technical manuals. Modern ingestion tools are evolving from rigid, batch-based processes to fluid, real-time pipelines. This shift is already yielding massive efficiency gains; for example, investment banks have reduced financial analysis cycles from 40 hours to under 90 minutes by automating data extraction.
2. Quality, Governance & Trust: The Guardrail Economy
As AI moves into production, the question has shifted from “can it work?” to “is it safe?”. This segment is the fastest-growing sub-sector, driven by the high cost of errors—an average of $12.9 million lost per enterprise in 2024 due to undetected data issues. With the rise of the EU AI Act, trust is now a technical requirement rather than a philosophical preference. Tools focusing on hallucination control and privacy-first curation are becoming essential “insurance” for AI investments.
3. Knowledge Engineering & Context: Enabling Agentic AI
The move toward autonomous AI agents has revitalized knowledge engineering. While standard models are often “memoryless,” this pillar provides the long-term memory and structured reasoning agents need to function as digital employees. GraphRAG has emerged as the gold standard here, using knowledge graphs to map relationships between data points rather than just searching for similar keywords. This allows AI to understand complex organizational hierarchies and interconnected project histories.
4. Training Data & Enrichment: The Synthetic Pivot
We are approaching a “data drought” where high-quality, human-generated internet data is being exhausted. The solution is the Synthetic Data Revolution. By creating artificial datasets that mirror the mathematical properties of real data, companies can train models without privacy risks or the limitations of real-world collection. This is particularly vital in robotics and autonomous driving, where “edge cases”—like a car driving through a blizzard—are too dangerous to collect manually but can be synthesized with perfect accuracy.
5. Discovery & Search: The Interface of Information
The “last mile” of curation is changing how we interact with data. We are seeing a structural shift from keyword-based search to “answer-based” discovery. In the retail sector, intelligent search now accounts for 42% of the market share, allowing customers to find products through conversational queries rather than rigid filters.
Economic and Social Drivers: Beyond the Hype
The expansion of this sector is driven by three distinct forces:
-
Technological: The rise of Multimodal AI requires pipelines that can synchronize video, audio, and text simultaneously.
-
Economic: There is a demonstrable ROI for organizations that get this right. 74% of organizations saw a return on investment within the first year of deploying AI agents.
-
Social: The “Privacy Paradox”. Consumers want personalized AI but distrust how their data is handled. Curation allows companies to satisfy these demands by anonymizing and de-identifying sensitive information before it touches a model.
Global Market Outlook for AI Data Curation
While North America remains the leader in infrastructure-heavy segments (holding 43.05% of the market in certain pillars), Asia and Europe are catching up quickly. Asia is a fast-adopter (30% share), while Europe’s growth is heavily influenced by its regulatory-centric landscape (25% share). Interestingly, regions like the UAE are “leapfrogging” Western adoption rates, with 64% of the population using AI daily compared to 28.3% in the US.
Strategic Takeaways for Business Leaders
To thrive in this new era, businesses must stop treating data curation as a back-office utility and start viewing it as an offensive economic strategy. Investing in high-fidelity ingestion, robust governance, and synthetic data pipelines is no longer optional—it is the only way to ensure AI models are accurate, unbiased, and compliant.
The message of the report is clear: in the race to AI dominance, the winner won’t necessarily be the one with the biggest model, but the one with the best-curated data.